



ubuntu@controller:~$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-565887c86b-kcp5z 1/1 Running 0 34h 10.1.131.5 microk8s70 <none> <none>
nginx-deployment-565887c86b-59d25 1/1 Running 0 34h 10.1.73.131 microk8s40 <none> <none>
ubuntu@controller:~$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.152.183.1 <none> 443/TCP 2d10h
nginx-service ClusterIP 10.152.183.23 <none> 8080/TCP 26hDemystifying Kubernetes Networking - Part I
How Kubernetes networking works under the hood; The networking model and Kubernetes Services.
Networking is an integral part of Kubernetes. But it could be confusing until you understand the basics.
The concept of networking in Kubernetes has two pieces.
How the IP packets traverse between Pods
How an IP packet originating at a client determines the destination Pod IP address.
Let’s try to understand these two pieces.
How the IP packets traverse between Pods
Kubernetes defines a networking model with two main requirements for IP packet traversal :
Each Pod gets an IP address that is unique within the cluster.
A Pod must be able to communicate with any other Pod in the same cluster without NAT (flat network model).
While it defines this networking model, Kubernetes does not implement it. The implementation of the networking model is the responsibility of the container runtime.
Popular container runtimes such as Containerd offloads the implementation of the networking model to Container Network Interface (CNI) network plugins. CNI is a set of specifications and libraries that governs how a network plugin must be implemented.
There are many implementations of CNI network plugins; both open-source and proprietary.
Calico and Flannel are the most popular open-source network plugins and are used in most on-premise Kubernetes deployments.
The leading cloud providers like AWS, Azure, and GCP, etc., have developed proprietary CNI plugins to interface with their networking implementations in the cloud. Networking solutions vendors like Cisco, Juniper, and Nuage offer proprietary CNI plugins with their SDN solutions for on-premise deployments.
To fulfill the requirements of the Kubernetes networking model, a network plugin implements two main features.
Assigns an IP address when a new Pod is created.
Implement Pod to Pod connectivity via a tunneling protocol such as VxLAN.

This tunneling mechanism is implementation-dependent and varies across CNI plugins but it ensures that any Pod can talk to any other Pod without NAT.
That solves the first piece of the problem.
How clients find the destination Pod IP address
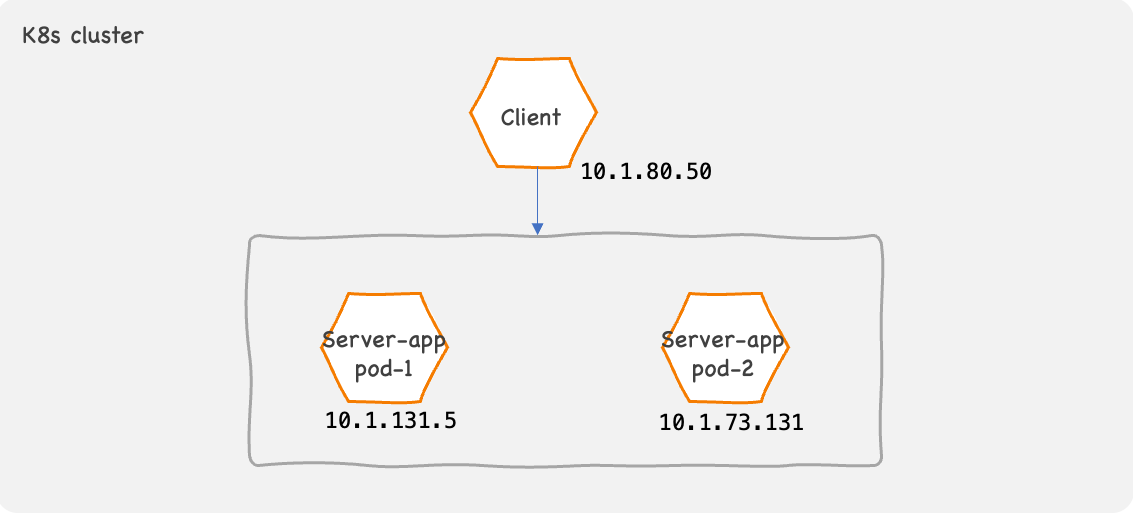
A Pod is an ephemeral object in Kubernetes.
Kubernetes can adjust the number of Pods in an application to match the load. Also, if there is a fault either in the node or in the code running in a container, Kubernetes destroys the problematic Pod and instantly recreates a new one. In such cases, the new Pod is assigned with a new IP address.
Due to this nature of Kubernetes, the number of available Pods and their IPs vary throughout the life span of a containerized application. This poses a problem for the clients.
How to determine the destination IP address of a server application?
It’s impossible for a client to keep track of the individual Pod IP addresses of all server applications. To solve this problem, Kubernetes implements the concept of Services.
Kubernetes Services
A Kubernetes Service is an abstraction of a group of Pods. It allows clients to talk to a server application without being concerned about the individual Pod IPs.

Kubernetes assigns a Service with a ClusterIP, which is a logical IP address. Clients can use the ClusterIP to talk to a server application. Traffic destined to the ClusterIP is loadshared across the Pods belonging to the Service.
Kubernetes also creates a DNS record for a service provided that a DNS add-on is enabled in the cluster. The DNS name of the Service is derived from the Service name so it can be predetermined. Instead of using the ClusterIP which is assigned at the time of creation, the clients can be pre-configured with the DNS name as well.
Since the ClusterIP is a logical IP address, it’s not assigned to any interface. A client Pod initiating communication with the Service, uses the ClusterIP as the destination address in the IP packets. To route these IP packets to any one of the Pods belonging to the service, worker nodes in the cluster implement a set of routing rules.
Kubernetes must update the routing rules to match the availability of the Pods. Older versions of Kubernetes (before v1.16) used EndPoint API objects to update the routing rules at each node.
An EndPoint holds the IP/port details of all the active Pods of a Service. When the status of a Pod changes, Kubernetes updates the EndPoint object and propagates it to all nodes. Each node then updates the routing rules.
This method has a scalability problem for Services with several hundreds of Pods. Each time a Pod status changes all the routing rules in each worker node must be updated demanding lots of CPU time of the worker nodes.
To overcome this problem EndPointSlices object was introduced. An EndPointSlice contains a reference of up to 100 Pods. A Service can have more than one EndPointSlice if the number of Pods exceed 100. If a Pod status changes, Kubernetes updates only the corresponding EndPointSlice. It reduces the number of routing rules that gets updated for each event easing the CPU demand.
Updating the routing rules in each worker node is the responsibility of the kube-proxy.
kube-proxy runs on every node in the cluster. By default, kube-proxy uses Linux iptables to implement the routing rules.
iptables is good enough for most applications. But, if there are tens of thousands of rules iptables become inefficient.
For such use cases. kube-proxy must use IPVS which is a transport layer loadbalancing method implemented in the Linux kernel. IPVS is scalable for Kubernetes clusters with thousands of Pods and services.
When using iptables, kube-proxy updates rules in the nat table to DNAT the traffic destined to any Service from Pods.
To see iptables in action, we have created a Service with two Pods in a three-node cluster.

Listing the Pods and Service.
List the nat table rules in one of the node microk8s70.
ubuntu@microk8s70:~$ sudo iptables -t nat -L PREROUTING
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
cali-PREROUTING all -- anywhere anywhere /* cali:6gwbT8clXdHdC1b1 */
KUBE-SERVICES all -- anywhere anywhere /* kubernetes service portals */
ubuntu@microk8s70:~$ sudo iptables -t nat -L KUBE-SERVICES
Chain KUBE-SERVICES (2 references)
target prot opt source destination
KUBE-SVC-WV6VKHDJQKB2TQC4 tcp -- anywhere 10.152.183.159 /* container-registry/registry:registry cluster IP */ tcp dpt:5000
KUBE-SVC-TCOU7JCQXEZGVUNU udp -- anywhere 10.152.183.10 /* kube-system/kube-dns:dns cluster IP */ udp dpt:domain
KUBE-SVC-ERIFXISQEP7F7OF4 tcp -- anywhere 10.152.183.10 /* kube-system/kube-dns:dns-tcp cluster IP */ tcp dpt:domain
KUBE-SVC-JD5MR3NA4I4DYORP tcp -- anywhere 10.152.183.10 /* kube-system/kube-dns:metrics cluster IP */ tcp dpt:9153
KUBE-SVC-IQGXNJVVP26VHMIN tcp -- anywhere 10.152.183.23 /* default/nginx-service:name-of-service-port cluster IP */ tcp dpt:http-alt
KUBE-SVC-NPX46M4PTMTKRN6Y tcp -- anywhere 10.152.183.1 /* default/kubernetes:https cluster IP */ tcp dpt:https
KUBE-NODEPORTS all -- anywhere anywhere /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCAL
ubuntu@microk8s70:~$ sudo iptables -t nat -L KUBE-SVC-IQGXNJVVP26VHMIN
Chain KUBE-SVC-IQGXNJVVP26VHMIN (1 references)
target prot opt source destination
KUBE-MARK-MASQ tcp -- !10.1.0.0/16 10.152.183.23 /* default/nginx-service:name-of-service-port cluster IP */ tcp dpt:http-alt
KUBE-SEP-CAK3XSESCB3K5VBO all -- anywhere anywhere /* default/nginx-service:name-of-service-port -> 10.1.131.5:8080 */ statistic mode random probability 0.50000000000
KUBE-SEP-M6K44XZSWZ6EUNHM all -- anywhere anywhere /* default/nginx-service:name-of-service-port -> 10.1.73.131:8080 */
ubuntu@microk8s70:~$ sudo iptables -t nat -L KUBE-SEP-CAK3XSESCB3K5VBO
Chain KUBE-SEP-CAK3XSESCB3K5VBO (1 references)
target prot opt source destination
KUBE-MARK-MASQ all -- 10.1.131.5 anywhere /* default/nginx-service:name-of-service-port */
DNAT tcp -- anywhere anywhere /* default/nginx-service:name-of-service-port */ tcp to:10.1.131.5:8080We can see that the traffic is loadshared in 50:50 ratio to the two Pods in the chain KUBE-SVC-IQGXNJVVP26VHMIN in the nat table.
The next chain KUBE-SEP-CAK3XSESCB3K5VBO implements DNAT.
kube-proxy creates routing rules in each worker node for all Services in a Kubernetes cluster so that a client in any node within the cluster can initiate communication with the Service.
But, this method does not work for clients outside the cluster.
To facilitate a client outside the cluster to talk to a Service within the cluster, Kubernetes provides several other methods.
NodePort
NodePort is a type of a Kubernetes Service which allows an external client to connect to a Pod via a specific port in worker nodes in the cluster.
To show how this works, we have deployed number-crunch application with two Pods. The number-crunch-service is a Service of type NodePort listening at TCP port 32155.
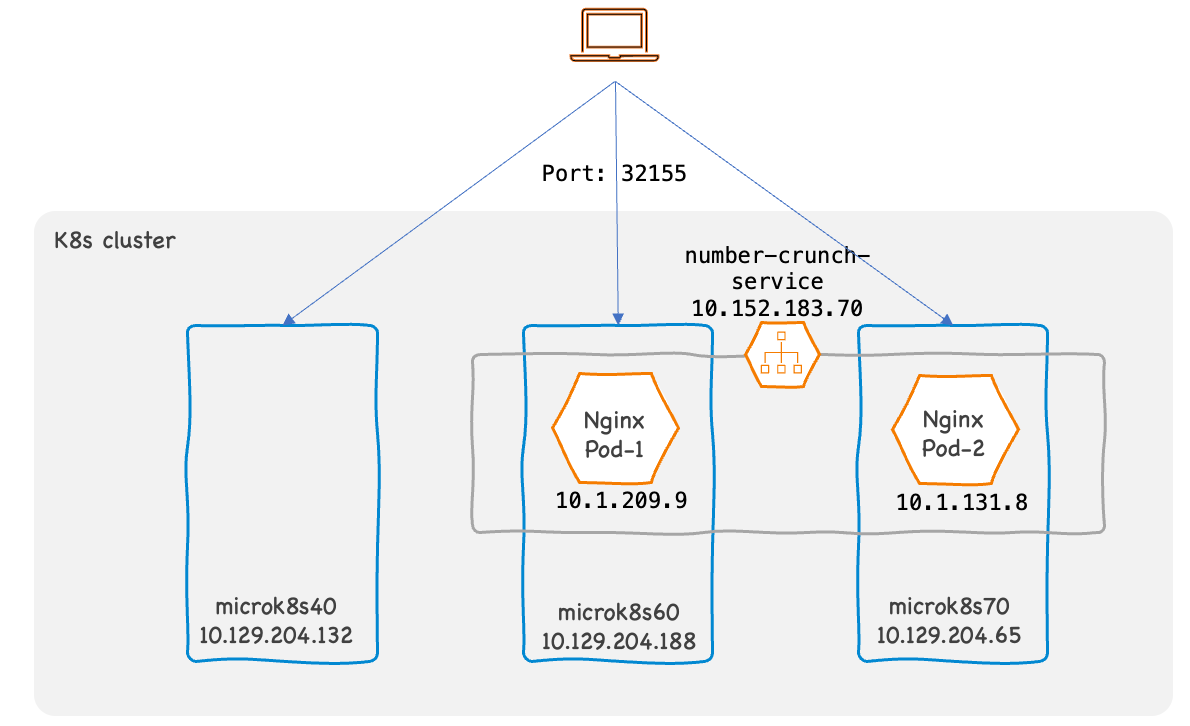
Listing the Kubernetes Service and Pods.
ubuntu@controller:~/kube-config$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.152.183.1 <none> 443/TCP 2d15h
number-crunch-service NodePort 10.152.183.70 <none> 8080:32155/TCP 10s
ubuntu@controller:~/kube-config$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
number-crunch-app-7b9d574b47-df4h5 1/1 Running 0 12s 10.1.209.9 microk8s60 <none> <none>
number-crunch-app-7b9d574b47-xv48x 1/1 Running 0 12s 10.1.131.8 microk8s70 <none> <none>
ubuntu@controller:~/kube-config$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
microk8s60 Ready <none> 2d7h v1.26.1 10.129.204.188 <none> Ubuntu 20.04.5 LTS 5.4.0-1082-kvm containerd://1.6.8
microk8s70 Ready <none> 2d7h v1.26.1 10.129.204.65 <none> Ubuntu 20.04.5 LTS 5.4.0-1082-kvm containerd://1.6.8
microk8s40 Ready <none> 2d16h v1.26.1 10.129.204.132 <none> Ubuntu 20.04.5 LTS 5.4.0-1082-kvm containerd://1.6.8Let’s test the service from the client which is outside the cluster.
ubuntu@client:~/projects/new-kube-config$ curl http://10.129.204.65:32155/square-root/4
{"InputNumber":4,"SquareRoot":2}
ubuntu@client:~/projects/new-kube-config$ curl http://10.129.204.132:32155/square-root/4
{"InputNumber":4,"SquareRoot":2}
ubuntu@client:~/projects/new-kube-config$ curl http://10.129.204.188:32155/square-root/4
{"InputNumber":4,"SquareRoot":2}All three worker nodes are responding to the request even though our application Pods are running on two of the nodes only.
Let’s check the iptables.
ubuntu@microk8s70:~$ sudo iptables -t nat -L KUBE-NODEPORTS
Chain KUBE-NODEPORTS (1 references)
target prot opt source destination
KUBE-EXT-PU6N6JOCTJFVBXKG tcp -- anywhere anywhere /* default/number-crunch-service:name-of-service-port */ tcp dpt:32155
KUBE-EXT-WV6VKHDJQKB2TQC4 tcp -- anywhere anywhere /* container-registry/registry:registry */ tcp dpt:32000
ubuntu@microk8s70:~$ sudo iptables -t nat -L KUBE-SVC-PU6N6JOCTJFVBXKG
Chain KUBE-SVC-PU6N6JOCTJFVBXKG (2 references)
target prot opt source destination
KUBE-MARK-MASQ tcp -- !10.1.0.0/16 10.152.183.70 /* default/number-crunch-service:name-of-service-port cluster IP */ tcp dpt:http-alt
KUBE-SEP-BSXDLRAU5RECNHND all -- anywhere anywhere /* default/number-crunch-service:name-of-service-port -> 10.1.131.8:8080 */ statistic mode random probability 0.50000000000
KUBE-SEP-ONGKSMQTWSGTWGGS all -- anywhere anywhere /* default/number-crunch-service:name-of-service-port -> 10.1.209.9:8080 */The rules for NodePort Services are created in the KUBE-NODEPORTS chain. As we can see, the first rule in that chain matches the packets destined to 32155 which is the port the number-crunch-service is listening to. It sends the packets to the next chain KUBE-SVC-PU6N6JOCTJFVBXKG which loadshare the packets to the two Pods.
These rules are created in each node even if no Pod belonging to the Service is running on the node. So, client can connect to the service via any node in the cluster.
NodePort allows an external client to talk to our Service, but it has a limitation. The client need to loadshare the traffic between the nodes.
To overcome this limitation we can use a Service of type LoadBalancer or a Kubernetes Ingress. We will explore this networking architecture in a future post.